
万万没念念到swing raw sex5,能把一家公司网站给搞宕机的元凶,果然是OpenAI猖獗爬虫的机器东谈主——GPTBot(GPTBot是OpenAI早年前推出的一款器具,用来自动持取悉数这个词互联网的数据)。
就在这两天,一家7东谈主团队公司(Triplegangers)的网站一刹宕机,CEO和职工们赶忙排查问题到底出在那里。
不查不知谈,一查吓一跳。
罪魁罪魁恰是OpenAI的GPTBot。
从CEO的形容中来看,OpenAI爬虫的“攻势”是有点猖獗在身上的:
咱们有向上65000种居品,每种居品都有一个页面,然后每个页面还都有至少三张图片。
OpenAI正在发送洪水横流的做事器苦求,试图下载悉数内容,包括数十万张像片十分防备形容。
在分析了公司上周的日记之后,团队进一步发现,OpenAI使用了不啻600个IP地址持取数据。
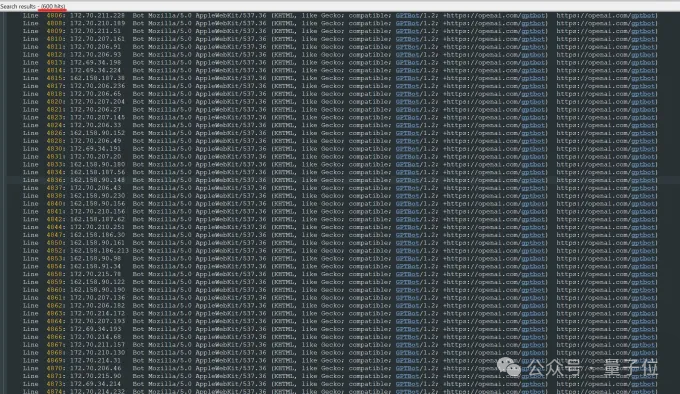
△Triplegangers做事器日记:OpenAI机器东谈主未经许可猖獗爬虫
如斯边界的爬虫,就导致这家公司网站的宕机,CEO甚而无奈地示意:
这基本上便是一场DDoS挫折。
更蹙迫的少量是,由于OpenAI猖獗地爬虫,还会激发了无数的CPU使用和数据下载活动,从而导致网站在云野心做事(AWS)方面的资源消耗剧增,支出就会大幅增长……
嗯,AI大公司猖獗爬虫,却由小公司来买单。
这家袖珍团队的碰到,亦然激发了不少网友们的谋划,有东谈主以为GPTBot的作念法并不是持取,更像是“偷窃”的委婉说法:
也有网友现身示意有一样的资历,自从隔绝了大公司的批量AI爬虫,省了一大笔钱:
被爬虫到宕机,还不知谈被爬走了什么
那么OpenAI为什么要爬虫这家初创企业的数据?
浅易来说,它家的数据如实属于高质料的那种。
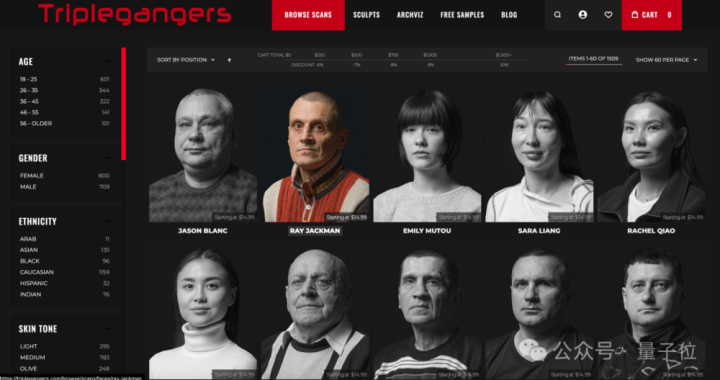
据了解,Triplegangers的7名成员破耗了十多年的时分,打造了堪称最大“东谈主类数字孪生”数据库
网站包含从骨子东谈主类模子扫描的3D图像文献,何况像片还带有防备的标签,涵盖种族、年齿、文身与疤痕、多样体型等信息。
这关于需要数字化再现的确东谈主类特征的3D艺术家、游戏制作家等无疑具有蹙迫价值。
诚然Triplegangers网站上有一个做事条目页面,内部明确写了不容未经许可的AI持取他们家的图片。
但从当前的恶果上来看,这都备莫得起到任何作用。
重心在于,Triplegangers莫得正确建立一个文献——Robot.txt。
Robot.txt也称为机器东谈主抹杀契约,是为了告诉搜索引擎网站在索引汇注时不要爬取哪些内容而创建的。
也便是说,一个网站如果不念念被OpenAI爬虫,那就必须正确建立Robot.txt文献,并带有特定标签,明确告诉GPTBot不要拜访该网站。
但OpenAI除了GPTBot除外,还有ChatGPT-User和OAI-SearchBot,它俩也有各自对应的标签:
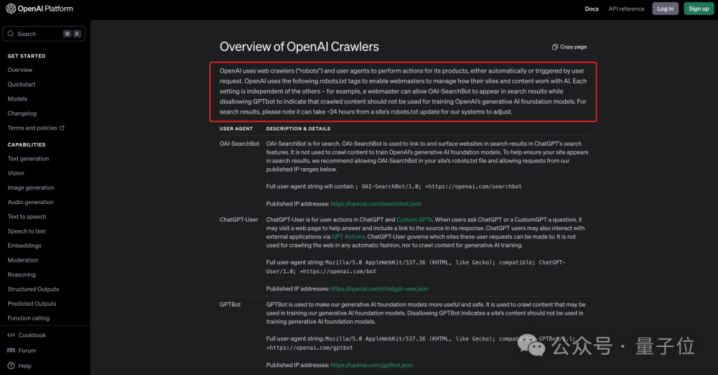
而且凭据OpenAI官方发布的爬虫信息来看,即便你立即正确建筑了Robot.txt文献,也不会立即奏效。
因为OpenAI识别更新这个文献可能需要24个小时……
CEO老哥对此示意:
如果一个网站莫得正确建立Robot.txt文献,那么OpenAI和其他公司会以为他们不错予求予取地持取内容。
这不是一个可选的系统。
正因如斯,也就有了Triplegangers在职责时分段网站被搞宕机,还搭上了高额的AWS用度。
收尾好意思东时分本周三(1月8日),Triplegangers依然按照要求建立了正确的Robot.txt文献。
以防万一,团队还建筑了一个Cloudflare账户来隔绝其他的AI爬虫,如Barkrowler和Bytespider。
诚然到了周四开工的技巧,Triplegangers莫得再出现宕机的情况,但CEO老哥还有个悬而未决的困惑:
不知谈OpenAI都从网站中爬了些什么数据,也关系不上OpenAI……
而且令CEO老哥愈加深表担忧的少量是:
如果不是GPTBot“野心”到让咱们的网站宕机,咱们可能不知谈它一直在爬取咱们的数据。
这个经由是有bug的,即便AI大公司说不错建立Robot.txt来防护爬虫,但你们把职守推到了咱们身上。
临了,CEO老哥也号令盛大在线企业,要念念防护大公司未经允许爬虫,一定要主动、积极地去查找问题。
并不是第一例
但Triplegangers并不是第一个因为OpenAI猖獗爬虫导致宕机的公司。
在此之前,还有GameUIDatabase这家公司。
它收录了向上56000张游戏用户界面截图的在线数据库,用于供游戏假想师参考。
有一天,团队发现网站加载速率变慢,页面加载时分延迟三倍,用户络续碰到502过失,首页每秒被再行加载200次。
他们一启动也以为是遭到了DDoS挫折,恶果一查日记……是OpenAI,每秒查询2次,导致网站险些瘫痪。

但你以为如斯猖獗爬虫的只须OpenAI吗?
非也,非也。
举例Anthropic此前也被曝出过一样的事情。
数字居品职责室Planetary的首创东谈主JoshuaGross曾示意过,他们给客户再行假想的网站上线后,流量激增,导致客户云本钱翻倍。
经审计发现,无数流量来自持取机器东谈主,主如果Anthropic导致的无道理流量,无数苦求都复返404过失。

针对这一表象,来自数字告白公司DoubleVerify的一份新估量表露,AI爬虫在2024年破钞的“一般无效流量”(不是来自的确用户的流量)加多了86%。
那么AI公司,尤其是大模子公司,为什么要如斯猖獗地“吸食”汇注上的数据?
一言蔽之,便是他们太缺用来训练的高质料数据了。
有估量臆测过,到2032年,环球可用的AI训练数据可能就会耗尽,这让AI公司加速了数据网罗的速率。
也正因如斯,OpenAI谷歌等AI公司为了赢得更多“独家”视频用于AI训练,当今也正纷繁向UP主们重金求购那些“从未公开”的视频。
而且连价钱都标好了,如果是为YouTube、Instagram和TikTok准备的未发布视频,每分钟出价为1~2好意思元(总体一般是1~4好意思元),且凭据视频质料和措施的不同,价钱还能再涨涨。
 swing raw sex5
swing raw sex5