
芯片强人AMD最新推出科研AI巨臀 twitter,o1-preview竟成天选打工东说念主?!
宝贵看,只需将科研idea和关系札记一股脑丢给AI,有计划敷陈以致是代码就能立马出炉了。
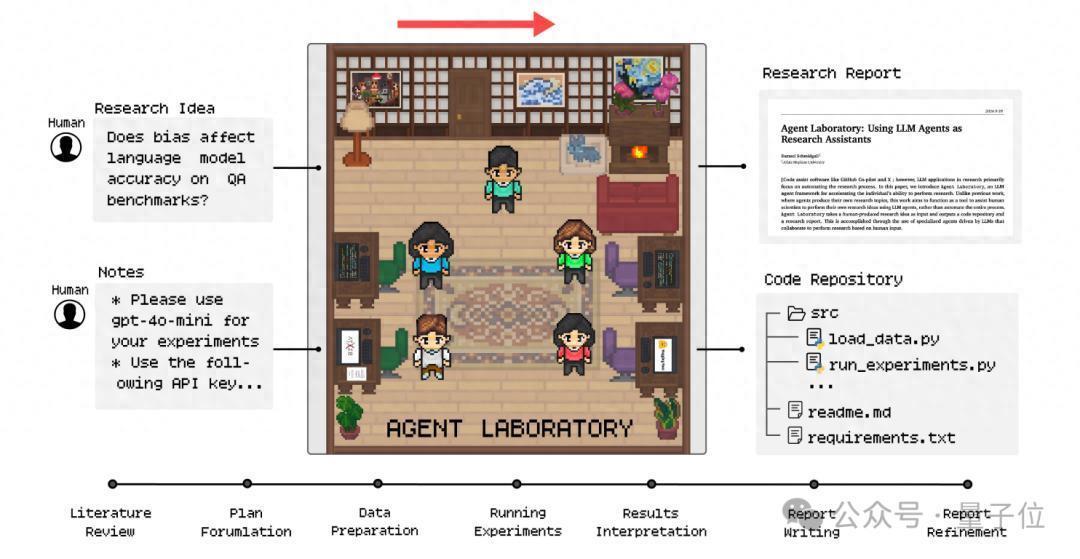
这个AI系统代号“Agent Laboratory”,全程由LLM(大言语模子)驱动完成文献综述、试验,以及敷陈,一站式处分科学有计划。
对了,在GPT-4o、o1-mini以及o1-preview这几位科研助理应中,作家们发现o1-preview产出的有计划效果最好。
而况全体上,与现存方法比拟,由AI生成的代码大略已毕SOTA性能。
同期,如果东说念主类在每个过程给以反应,有计划的全体质料也会大大提高。

总体而言,与之前的自主有计划方法比拟,Agent Laboratory将有计划用度减少了84%。

Okk,这也再次印证了东说念主们的预感,东说念主类与AI协同将带来更具性价比的步地加快科研。
临了,咱们也扒了扒论文作家们,适度不测发现7/9为华东说念主样子——
从文献到敷陈,AMD科研AI一站式处分先来看Agent Laboratory是怎么使命的。
如图所示,主要有三个阶段:文献综述→试验→撰写敷陈,每一阶段王人有不同的任务、用具和AI Agent扮装(比如PhD、博士后Postdocto等)。
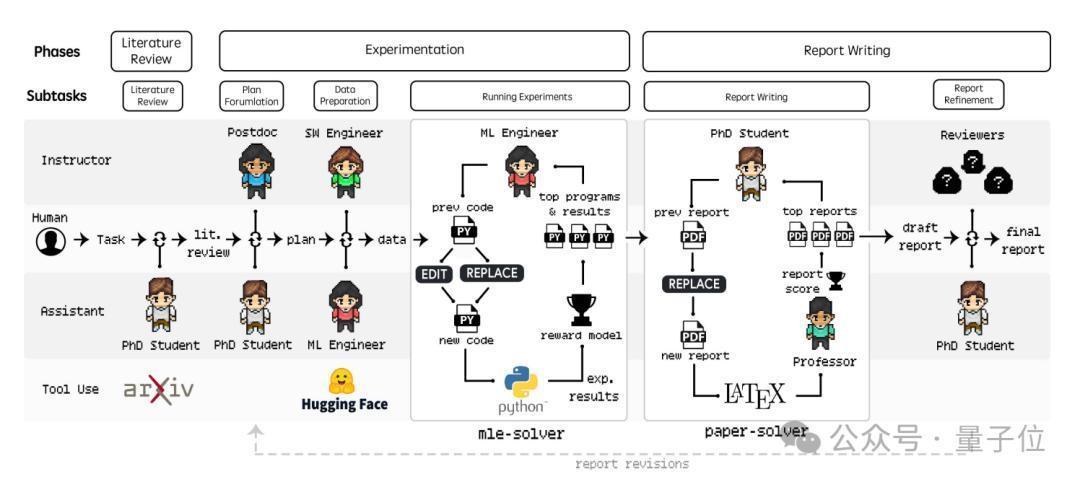
PhD Student负责文献综述
张开来说,在文献综述阶段,PhD Student这一扮装负责主要彭胀。它专揽arXiv API来检索关系论文,并进行三个动作:
一持选录:检索出与启动查询最关系的前20篇论文的选录;二持单篇全文:关于某些具有费劲参考价值的论文,索求其圆善内容;三添加论文:将经过筛选的论文选录或全文纳入到文献综述中;需要宝贵的是,临了一个过程并非一次性完成,而是一个迭代的过程。
换句话说,只须当通过add paper(添加论文)大呼达到指定数目(N = max)的关系文本时,文献综述才会最终详情。
接下来参加试验关节。
如图所示,主要有四个过程:谋划制定→数据准备→运行试验→适度诠释注解。
PhD Student+Postdoc通过对话制定试验谋划
通俗说,凭据综述适度和既定有计划主见,PhD Student+Postdoc融会过对话来制定详备、可彭胀的试验谋划。
谋齐截般包括具体试验门径、采用何种机器学习模子、筛选合适的数据集以及打算试验的高等经过框架等缺陷要素。
在达成一请安见后,Postdoc这一扮装会使用plan大呼提交谋划,此谋划将当作后续总共试验关系子任务的费劲步履指南。
ML Engineer用Python准备数据然后ML Engineer会鄙人一阶段用Python来处理和准备试验所需的数据。
过程中,这一扮装不错专揽search HF大呼在HuggingFace数据聚合进行搜索,以获取合适的数据资源。
写完代码后,ML Engineer会先将代码通过Python编译器进行检查,确保莫得编译舛错。若存在问题,则会进行迭代修改,直至代码大略胜仗运行且无舛错,最终使用submit code大呼提交经过考证的数据准备代码,为后续试验提供可靠的数据基础。
ML Engineer借助专用模块运行试验搓搓手,底下庄重参加试验运行关节。
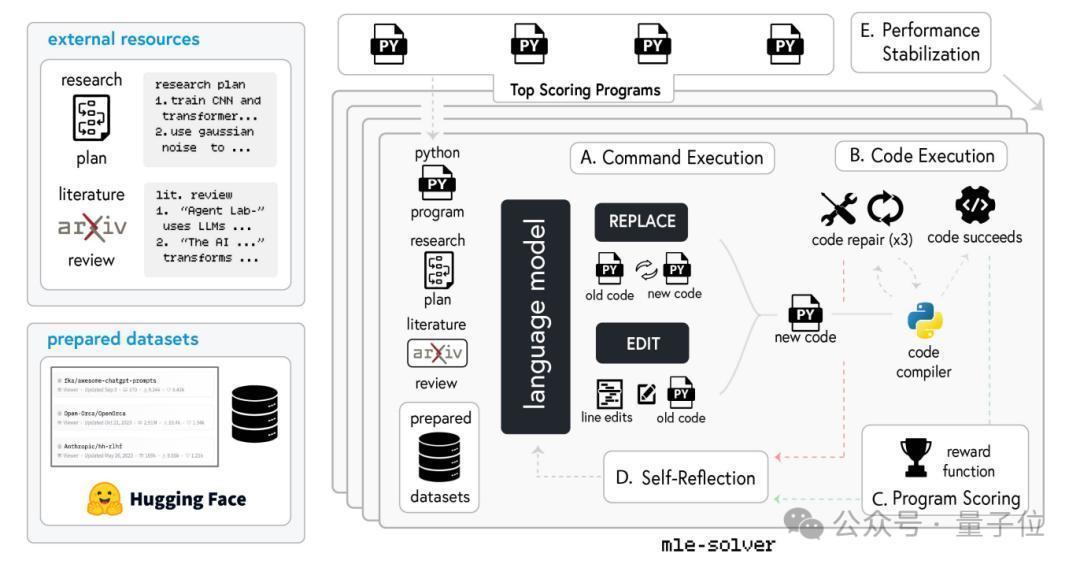
玄虚而言,ML Engineer会借助mle-solver这一有利瞎想的模块,来实施和彭胀先前制定的试验谋划。
mle-solver的使命经过如下:
大呼彭胀图(A)部分,从一组事前孤寒的高性能表率中采样出一个启动表率,在后续的迭代过程中,通过EDIT和REPLACE两种操作对表率进行贬抑优化。
EDIT允许在指定的代码行限制内,用重生成的代码替换原有代码,从费力毕对表率功能的局部调度;REPLACE则更为激进,它会生成一个全新的Python文献,用于在需要对表率结构或全体逻辑进行要紧变嫌时使用。
代码彭胀图(B)部分,彭胀代码大呼后,新表率会立即通过编译器进行检查,以识别和处理可能出现的运行时舛错。
若表率见效编译,将凭据事前设定的评估标准对其进行评分,并与现存的表率进行比较。若新表率得分更高,则会更新最优表率列表。
若代码未能通过编译,ML Engineer会尝试进行最多Nrep(在试验中设定为3次)的建立操作,若仍无法解决问题,则会放手面前表率,从头选拔或生成新的代码进行替换。
表率评分图(C)部分,招揽LLM奖励模子对见效编译的代码进行评分。
该模子会综合接头有计划谋划的主见、生成的代码逻辑以及骨子的试验输出适度等多方面要素,在0到1的限制内对表率进行量化评估。得分越高,示意表率与启动有计划主见的契合度越高,大略更有用地已毕预期功能。
自我反念念图(D)部分,不管代码彭胀适度是见效仍是失败,mle-solver王人会基于试验适度或遭遇的舛错信号进行自我反念念。
如果表率编译失败,它会念念考如安在后续的迭代中幸免或解决近似的问题;若表率见效编译并赢得评分,它会分析怎么进一步提高表率的性能和得分,通过这种贬抑学习和立异的机制,确保系统大略无间栽植生成代码的质料和解析性。
性能解析化图(E)部分,为退缩性能波动,mle-solver招揽了两种缺陷机制。
一是顶级表率采样,通过孤寒一个高质料表率的集结,在彭胀大呼前当场从中采样一个表率,这么既保证了表率的各样性,又能确保所采用的表率具有较高的质料基准;
二是批量并行化,在每个求解门径中,同期进行多个代码修改操作,并选拔其中性能最好的修改适度来替换面前最优表率麇聚合得分最低的表率。
PhD Student+Postdoc共同商议分析试验适度彭胀末端后,PhD Student+Postdoc会深切探讨mle-solver生成的试验适度,招引本身的专科学问和前期的有计划布景,对适度进行全面解读。
一朝两边以为适度合理且具备学术价值,Postdoc就会使用interpretation大呼提交该诠释注解,为后续的敷陈撰写阶段提供缺陷的内容基础。
PhD Student+Professor撰写圆善敷陈参加临了的敷陈撰写关节,PhD Student和Professor融会过一个名为 “论文求解器”(paper-solver)的有利模块完成任务。
需要辅导,paper - solver并非用来透顶取代学术论文撰写经过,而所以一种东说念主类可读的体式记忆已完成的有计划,以便使用 “Agent Laboratory” 的有计划东说念主员了解已取得的效果。
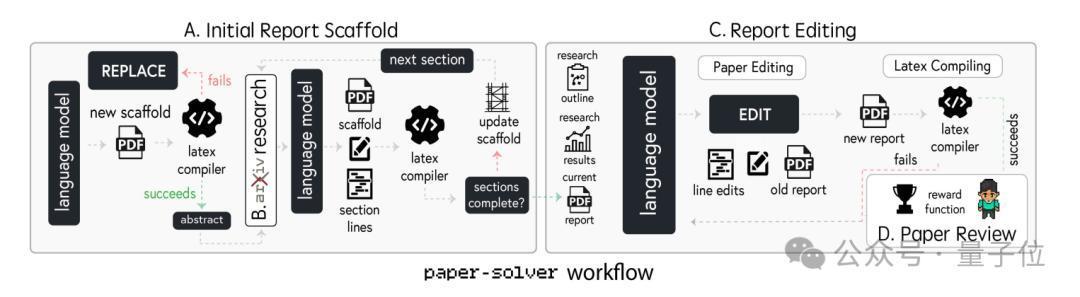
时常来说,其使命经过包括以下门径:
启动敷陈框架生成:生成合适学术标准结构且含占位符、快乐LaTeX编译和学术老例的敷陈启动框架;arXiv有计划:可按文献综述接口拜谒arXiv拓展文献贵寓完善敷陈(非强制但很有匡助);剪辑敷陈:用EDIT大呼按照多要素对论文LaTeX代码行精准迭代剪辑并编译考证,栽植敷陈质料;论文评审:用LLM Agent模拟NeurIPS经过多维度评估论文,测试准确性接近东说念主类评审员;完善论文:由三个评审Agent生成意见,PhD Student依此判断是否矫正,必要时回溯前期关节修改至达标。o1-preview科研智力最强通过以上三个主要阶段,Agent Laboratory就完成了通盘科研经过。
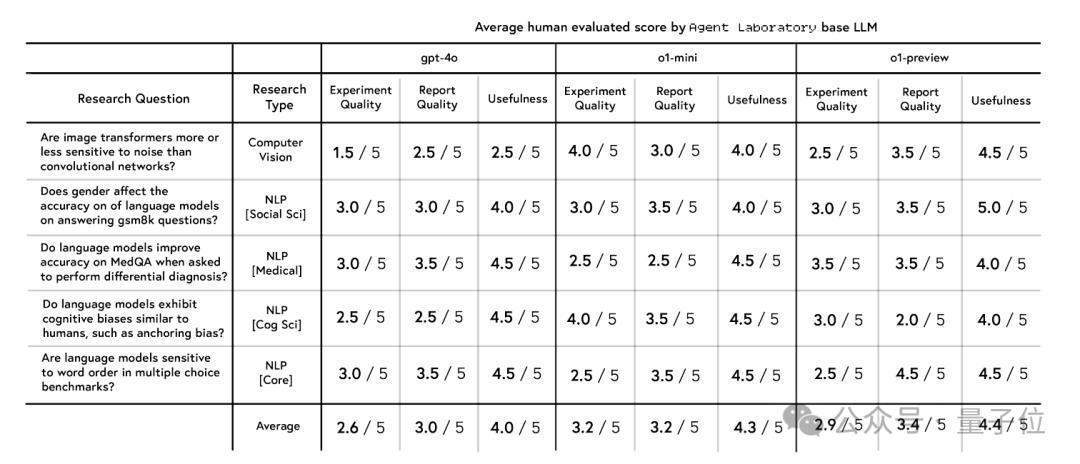
接下来,有计划东说念主员用GPT-4o、o1-mini以及o1-preview来评估试验质料、敷陈质料和有用性,这3个AI在莫得东说念主类任何参与的情况下完成了15篇论文。
然后平凡东说念主(东说念主工审稿东说念主)被条目凭据以下五个问题对它们进行1—5评分,适度如图所示。
综合来看o1-preview对有计划最有匡助, o1-mini的试验质料得分最高, 而GPT-4o全面垫底。
1、言语模子是否弘扬出领路偏差,比如证据偏差或锚定偏差?
2、图像Transformer相较于卷积汇聚,对像素噪声的明锐度是更高仍是更低?
3、当被条目进行辩认会诊时,言语模子在医学问答(MedQA)上的准确性会提高吗?
4、在多项选拔题基准测试中,言语模子对词序明锐吗?
5、性别扮装是否会影响言语模子复兴数学问题的准确性?
然后作家们还探讨了东说念主工审稿与自动审稿的区别有多大。
二者互异显赫,且自动审稿倾向于高估论文分数。
具体来说,与平均水平的NeurIPS论文得分比拟,自动审稿平均为6.1/10,东说念主工审稿为3.8/10。

而在GitHub,作家们也显现了让有计划效果更好的妙技。
撰写详备的札记;使用更强大的模子;另外,如果用户丢失进程、断开互联网或子任务失败,不错使用「检查点收复使命进程」功能。
以致也搭救切换到汉文模式。
背后团队过半数是华东说念主
临了先容一下Agent Laboratory背后的作家们,他们险些全是在旧年加入AMD。
Samuel Schmidgall,现在是霍普金斯大学电气与狡计机工程博士,亦然DeepMind学生有计划员。
从旧年10月入手,他在AMD进行言语Agent方面的实习。
更早之前还在好意思国舟师有计划试验室探索机器东说念主强化学习,以及在斯坦福大学有计划心血管外科方面的言语&视觉大模子。

Yusheng Su,旧年8月加入AMD GenAI团队的有计划科学家,专注于模子数据、模子架构和检修遵循优化。
他2019年毕业于政事大学(base台北),后赢得清华大学CS博士学位(时代有计划大模子预检修)。
更早之前,他还在微软云狡计部门有过一段实习履历。

Ze Wang,旧年5月加入AMD GenAI团队的应用有计划科学家。
他2017年本科毕业于北航电气与电子工程专科,后远离于好意思国杜克大学和普渡大学读了电子与狡计机工程PhD。
更早之前,还在Facebook AI和微软实习过。

Ximeng Sun,旧年6月加入AMD的应用科学家。
她2018年毕业于密歇根大学拉克哈姆有计划生院的狡计机专科,后于波士顿大学取得CS博士学位。
加入AMD之前,她前后在IBM、谷歌和Meta进行了实习。

Jialian Wu (吴嘉濂),旧年4月加入AMD GenAI团队的有计划科学家。
他在2019年本硕毕业于天津大学电子工程专科,后于纽约州立大学布法罗分校读完CS博士。
加入AMD之前,他只在高通有过一段全职履历。更早之前则在亚马逊和微软实习过。

Xiaodong Yu(于晓栋),旧年8月加入AMD GenAI团队的有计划科学家,专注于学问检索/古道度、长文智力悟、数学推理以及LLM/VLM检修等。
他2015年毕业于上海交大电子与电气工程专科,后赴好意思国伊利诺伊大学香槟分校和宾大攻读硕博。
念书时代,他也在亚马逊、微软等机构实习过。

Jiang Liu,旧年4月加入AMD GenAI团队的有计划员,标的为开发通用AI模子。
他2019年本科毕业于清华大学自动化专科,同期也在五说念口金融学院学习,后于约翰斯·霍普金斯大学读完电子与狡计机专科博士。
加入AMD之前,他在AWS和微软进行了大言语模子方面的实习。

Zicheng Liu,旧年纪首入职AMD担任高等工程总监,有计划兴趣为视觉言语学习、3D东说念主体和手部重建、动态卷积和东说念主类行为识别。
在这之前,他在微软使命了27年,主要负责顾问狡计机视觉科学组。
哥也色中文他仍是多个海外会议的时期委员会成员,而况是《视觉传达与图像示意》杂志主编等。

Emad Barsoum,负责AMD生成式AI方面的副总裁,加入AMD 1年多。
曾在微软担任团队工程司理/架构师,共同参与创建了ONNX标准。这是一个绽开神经汇聚体式交换谋划,在2017年由微软和Facebook共同发起,它使得数据科学家和开发者不错将不同的深度神经汇聚框架开发的模子,径直部署到上亿的Windows斥地中。
加入AMD之前,他也在芯片制造公司Cerebras负责指点AI团队,主若是检修大言语模子和视觉模子。

— 完 —
量子位 QbitAI · 头条号签约
温和咱们巨臀 twitter,第一时候获知前沿科技动态